


3D Computer Vision is a branch of computer science that focuses on acquiring, image processing, and analyzing three-dimensional visual data. It aims to reconstruct and understand the 3D structure of objects and scenes from two-dimensional images or video data. 3D vision techniques use information from sources like cameras or sensors to build a digital understanding of the shapes, structure, and properties of objects in a scene. This has numerous applications in robotics, augmented/virtual reality, autonomous systems, and many more.
This article will break down the fundamentals of 3D computer vision and its significance. Throughout the article, you’ll gain the following insights:
- Definition and scope of 3D computer vision
- Fundamental concepts in 3D computer vision
- Passive and active techniques of 3D reconstruction in computer vision
- Deep learning approaches like 3D CNN, Point Cloud Processing, 3D Object Detection, etc.
- How do 3D reconstruction techniques extract information from 2D images?
- Applications
- Ethical considerations involved while implementing 3D computer vision models
What is 3D Computer Vision?
3D computer vision systems extract, process, and analyze 2D visual data to generate their 3D models. To do so, it employs different algorithms and data acquisition techniques that enable computer vision models to reconstruct the dimensions, contours, and spatial relationships of objects within a given visual setting. The 3D CV techniques combine principles from multiple disciplines, such as computer vision, photogrammetry, geometry, and machine learning to derive valuable three-dimensional information from images, videos, or sensor data.
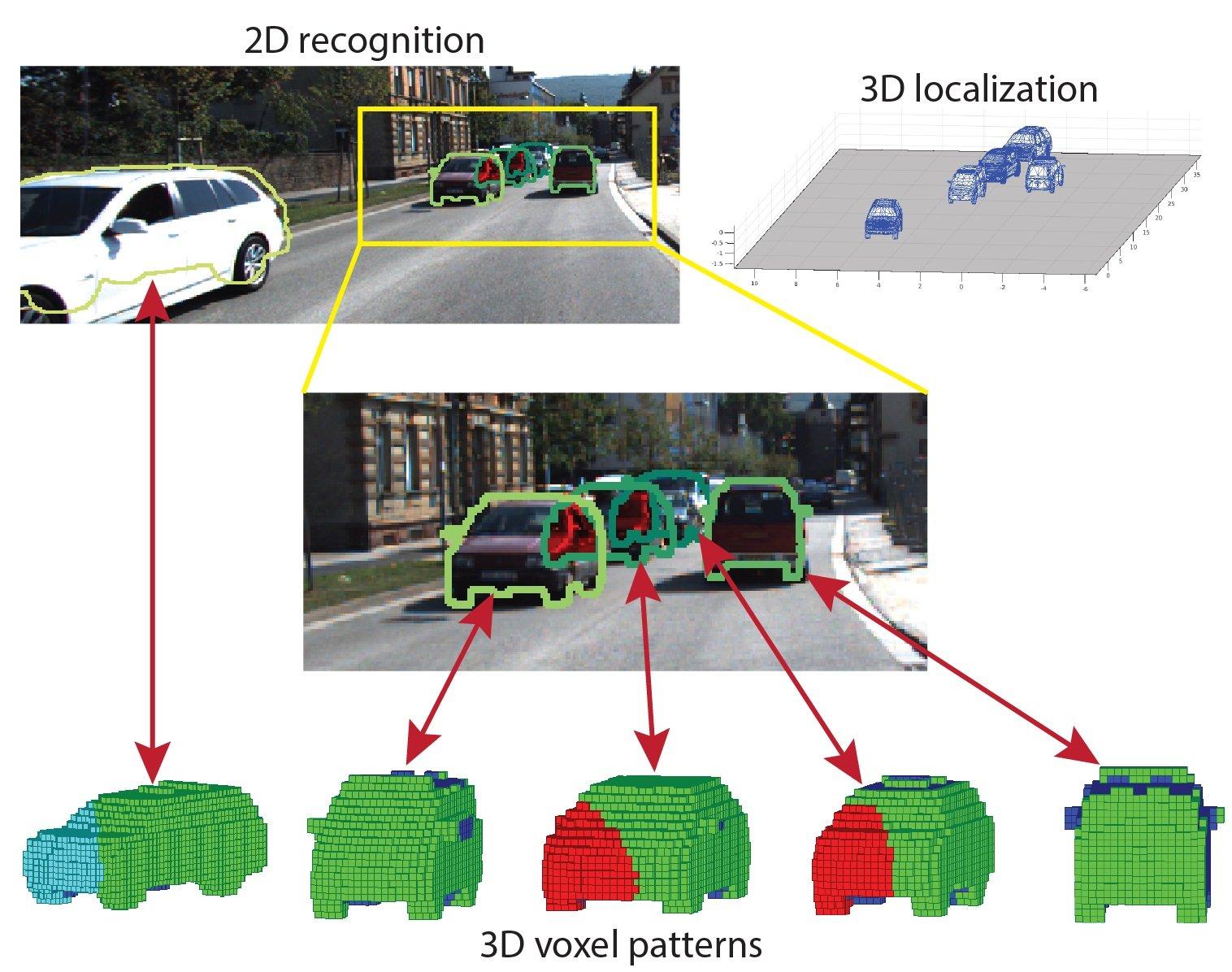
Fundamental Concepts in 3D Computer Vision
1. Depth Perceptions
Depth perception is the ability to estimate the distance between objects and the camera or sensor. This is accomplished through methods like stereo vision, where two cameras are used to calculate depth or by analyzing cues such as shading, texture changes, and motion differences in single-camera images or video sequences.
2. Spatial Dimensions
Spatial dimensions refer to the three orthogonal axes (X, Y, and Z) that make the 3D coordinate system. These dimensions capture the height, width, and depth values of objects. Spatial coordinates facilitate the representation, examination, and manipulation of 3D data like point clouds, meshes, or voxel grids essential for applications such as robotics, augmented reality, and 3D reconstruction.
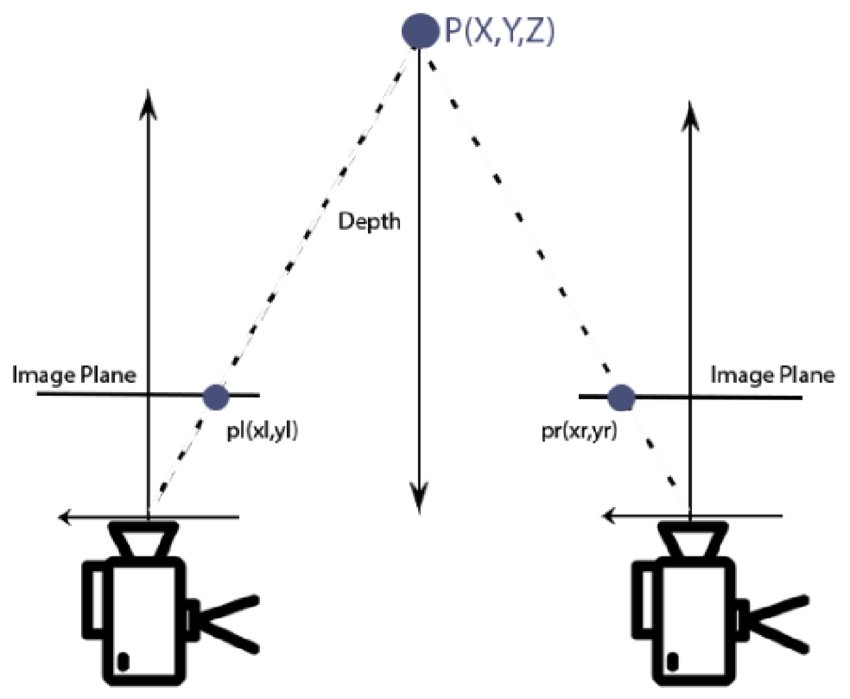
3. Homogeneous Coordinates and 3D Projective Geometry
3D projective geometry and homogeneous coordinates offer a structure for representing and handling 3D points, lines, and planes. Homogeneous coordinates represent points in space using an additional coordinate to allow geometric transformations like rotation, translation, and scaling through matrix operations. On the other hand, 3D projective geometry deals with the mathematical representation and manipulation of 3D objects along with their projections onto 2D image planes.
4. Camera Models and Calibration Techniques for 3D Models
The appropriate selection of camera models and their calibration techniques play a crucial role in 3D CV to precisely reconstruct 3D models from 2D images. The use of high-definition camera models improves the geometric relationship between 3D points in the real world and their corresponding 2D projections on the image plane.
Meanwhile, accurate camera calibration helps estimate the camera’s intrinsic parameters, such as focal length and principal point, as well as extrinsic parameters, including position and orientation. These parameters are crucial for correcting distortions, aligning images, and triangulating 3D points from multiple views to ensure accurate reconstruction of 3D models.
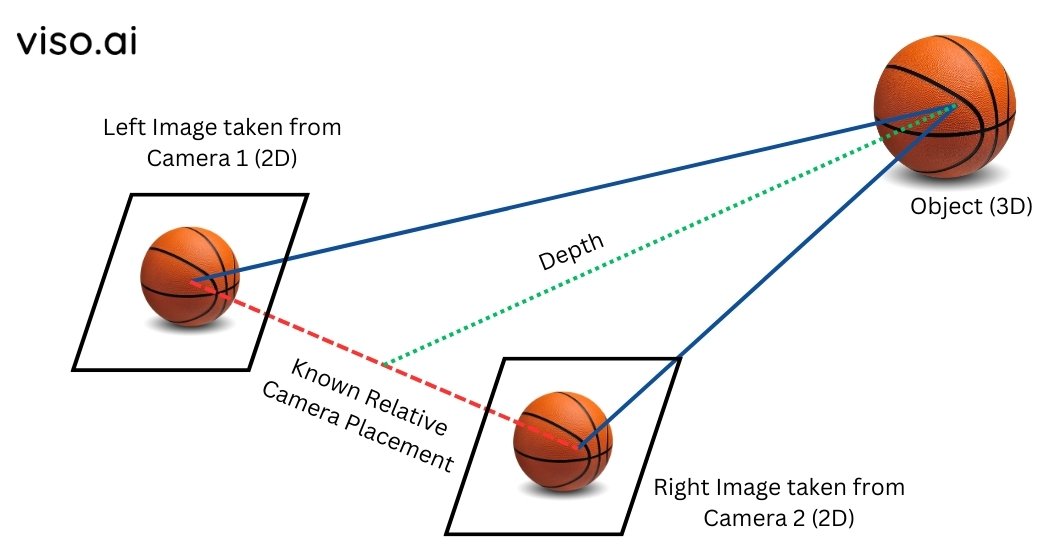
5. Stereo Vision
Stereo vision is a method in 3D CV that utilizes two or more 3D machine vision cameras to capture images of the same scene from slightly different angles. This technique works by finding matching points in both images and then calculating their 3D locations using the known camera geometry. Stereo vision algorithms analyze the disparity or the difference in the positions of corresponding points to estimate the depth of points in the scene. This depth data allows the accurate reconstruction of industry 3D models, which can be useful for tasks like robotic navigation, augmented reality, and 3D mapping.
In computer vision, we can create 3D models of objects in two main ways: using special sensors (active) or just regular cameras (passive). Let’s discuss them in detail:
Passive Techniques 3D Reconstruction
Passive imaging techniques directly analyze images or videos captured by existing light sources. They achieve this without projecting or emitting any additional controlled radiation. Examples of these techniques include:
Shape from Shading
In 3D computer vision, shape from shading reconstructs an object’s 3D shape using just a single 2D image. This technique analyzes how light hits the object (shading patterns) and how bright different areas appear (intensity variations). By understanding how light interacts with the object’s surface, this vision technique estimates its 3D shape. Shape from shading assumes we know the surface properties of objects (especially how they reflect light) and the lighting conditions. Then, it uses special algorithms to find the most likely 3D shape of that object that explains the shading patterns seen in the image.
Shape from Texture
Shape from texture is a method used in computer vision to determine the three-dimensional shape of an object based on the distortions found in its surface texture. This technique relies on the assumption that the surface possesses a textured pattern with known characteristics. By analyzing how this texture appears deformed in a 2D image, this technique can estimate the 3D orientation and shape of the underlying surface. The fundamental concept is that the texture will be compressed in areas facing away from the camera and stretched in areas facing toward the camera.
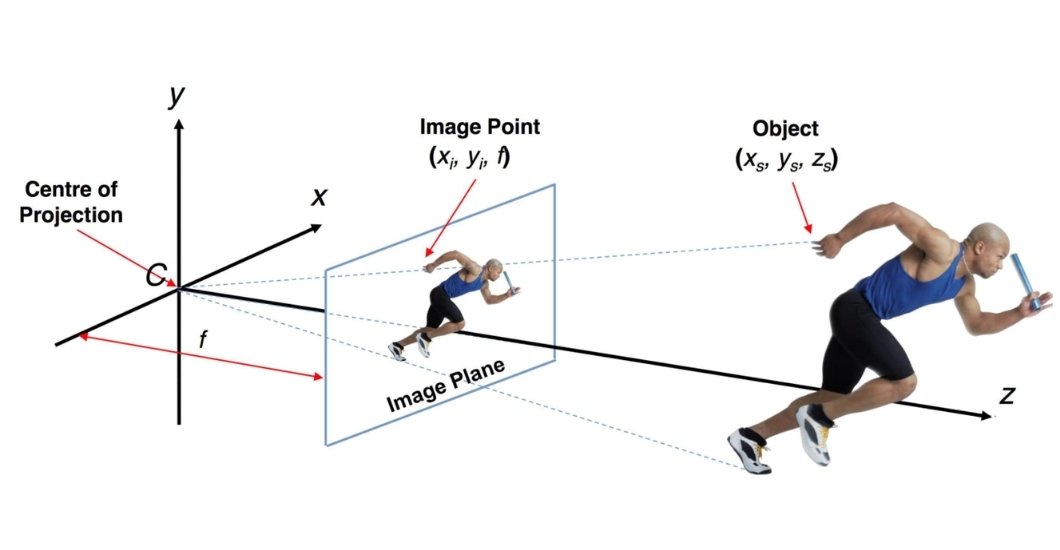
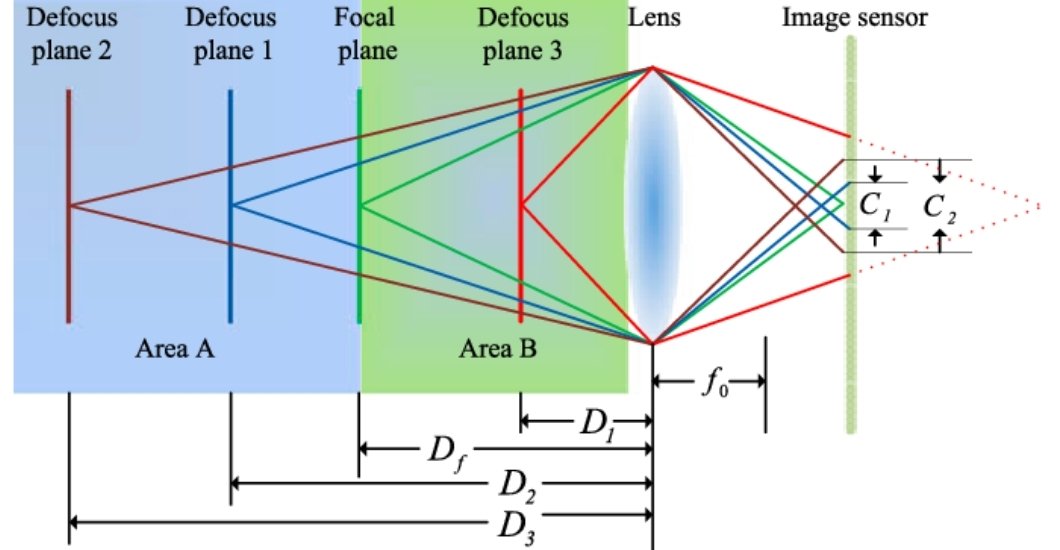
Depth from Defocus
Depth from defocus is a process that calculates the depth or three-dimensional structure of a scene by examining the degree of blur or defocus present in areas of an image. It works on the principle that objects situated at distances, from the camera lens will exhibit varying levels of defocus blur. By comparing these blur levels throughout the image, DfD can generate depth maps or three-dimensional models representing the scene.
Structure from Motion (SfM)
Structure from Motion (SfM) reconstructs the 3D structure of a scene from a set of 2D images. It captures a set of overlapping 2D images as input. We can capture these images with a regular camera or even a drone.
The first step identifies common features across these images, such as corners, edges, or specific patterns. SfM then estimates the position and orientation (pose) of the camera for each image based on the identified features and how they appear from different viewpoints. By having corresponding features in multiple images and the camera poses, it performs triangulation to determine the 3D location of these features in the scene. Lastly, the SfM algorithms use the 3D positioning of these features to build a 3D model of the scene which can be a point cloud representation or a more detailed mesh model.
Active Techniques 3D Reconstruction
Active 3D reconstruction methods project any kind of radiation, like light, sound, or radio waves onto the object. It then analyzes their reflections, echoes, or distortions to reconstruct the 3D structure of that object. Examples of such techniques may include:
Structured Light
Structured light is an active 3D CV technique where a specifically designed light pattern or beam is projected onto a visual scene. This light pattern can be in various forms including grids, stripes, or even more complex designs. As the light pattern strikes objects that have varying shapes and depths, the light beams get deformed. Therefore by analyzing how the projected beams bend and deviate on the object’s surface, a vision system calculates the depth information of different points on the object. This depth data allows for reconstructing a 3D representation of the visual object that is under observation.
Time-of-Flight (ToF) Sensors
Time-of-flight (ToF) sensor is another active vision technique that measures the time it takes for a light signal to travel from the sensor to an object and back. Common light sources for ToF sensors are lasers or infrared (IR) LEDs. The sensor emits a light pulse and then calculates the distance based on the time-of-flight of the reflected light beam. By capturing this time for each pixel in the sensor array, a 3D depth map of the scene is generated. Unlike regular cameras that capture color or brightness, ToF sensors provide depth information for every point which essentially helps in building a 3D image of the surroundings.
LiDAR
LiDAR (Light Detection and Ranging) is a remote sensing 3D vision technique that uses laser light to measure object distances. It emits laser pulses towards objects and measures the time it takes for the reflected light to return. This data generates precise 3D representations of the surroundings. LiDAR systems create high-resolution 3D maps that are useful for applications like autonomous vehicles, surveying, archaeology, and atmospheric studies.
Deep Learning Approaches to 3D Vision (Advanced Techniques)
Recent advancements in deep learning have significantly impacted the field of 3D Computer Vision. It has achieved remarkable results in various tasks such as:
3D CNNs
3D convolutional neural networks, also known as 3D CNNs are a form of 3D deep learning model crafted for analyzing three-dimensional visual data. In contrast to traditional CNN approaches that process 2D data, 3D CNNs leverage unique filters to extract key features directly from volumetric data, such as 3D medical scans or object models in three dimensions. This capability to process data in three dimensions enables this learning approach to capture spatial relationships (such as object positioning) and temporal details (like motion progression in videos). As a result, 3D CNNs prove effective for tasks like 3D object recognition, video analysis, and precise segmentation of medical images for accurate diagnoses.

Point Cloud Processing
Point Cloud Processing is a method used in 3D deep learning to examine and manipulate 3D visual data presented as point clouds. A point cloud is a set of 3D coordinates typically captured by devices such as scanners, depth cameras, or LiDAR sensors. These coordinates indicate the object positions and sometimes additional information like intensity or color for each point within a visual environment. The processing tasks include aligning scans (registration), segmenting objects, eliminating noise (denoising), and generating 3D models (surface reconstruction) based on the points data. This approach is applied in computer vision to recognize objects, 3D scene understanding, and develop 3D maps essential for applications like autonomous vehicles and virtual reality.
3D Object Recognition and Detection
3D object recognition aims to identify and locate objects within a visual scene but with the added complexity of the third dimension - depth. It analyzes features like shape, texture, and potentially 3D information to classify the object. This involves drawing bounding boxes around the object or generating a point cloud that represents its shape. This vision technique takes recognition a step further. It identifies the object as well as its exact location in the 3D space. Think of it as a self-driving car that not only recognizes a pedestrian but also pinpoints their distance and position on the road.

How Do 3D Reconstruction Techniques Extract Information from 2D Images?
The process of extracting three-dimensional information from two-dimensional images involves several steps:
Step 1: Capturing the Scene:
We start by taking pictures of the object or scene from different angles, sometimes under varied lighting conditions (depending on the technique).
Step 2: Finding Key Details:
From each image, we extract important features like corners, edges, textures, or distinct points. These act as reference points for later steps.
Step 3: Matching Across Views:
We identify matching features between different pictures, essentially connecting the same points seen from various angles.
Step 4: Camera Positions:
Using the matched features, we estimate the location and orientation of each camera used to capture the images.
Step 5: Going 3D with Triangulation:
Based on the matched features and camera positions, we calculate the 3D location of those corresponding points in the scene. Think of it like intersecting lines of sight from different viewpoints to pinpoint a spot in 3D space.
Step 6: Building the Surface:
With the 3D points in place, we create a surface representing the object or scene. This often involves techniques like Delaunay triangulation, Poisson surface reconstruction, or volumetric methods.
Step 7: Adding Texture (Optional):
If the original images have color or texture information, we can map it onto the reconstructed 3D surface. This creates a more realistic and detailed 3D model.
Real-World Applications of 3D Computer Vision
The advancements in 3D Computer Vision have paved the way for a wide range of applications:
AR/VR Technology
3D vision creates immersive experiences in AR/VR by building virtual environments. It adds overlays onto real views and enables interactive simulations.
Robotics
Robots use 3D vision to “see” their surroundings. This allows them to navigate and recognize objects in complex real-world situations.
Autonomous Systems
Self-driving cars, drones, and other autonomous systems rely on 3D vision for crucial tasks. These include detecting obstacles, planning paths, understanding scenes, and creating 3D maps of their environment. This all ensures the safe and efficient operation of autonomous vehicles.
Medical Imaging and Analysis
3D machine vision systems are vital in medical imaging. They reconstruct and visualize 3D anatomical structures from CT scans, MRIs or ultrasounds that aid doctors in diagnosis and treatment planning.
Surveillance and Security
3D vision systems can monitor and analyze activities in real-time for security purposes. They can detect and track objects or people, monitor crowds and analyze human behavior in 3D environments.
Architecture and Construction
3D computer vision techniques help in creating detailed 3D models of buildings and environments. This helps with design, planning and creating virtual simulations for architecture and construction projects.
Ethical Considerations in 3D Vision Systems
3D computer vision offers impressive capabilities but it’s important to consider ethical issues. Here’s a breakdown:
- Bias: Training data with biases can lead to unfair outcomes in facial recognition and other applications.
- Privacy: 3D systems can collect detailed information about people in 3D spaces which raises privacy concerns. Moreover getting informed consent is very difficult, especially in public areas.
- Security: Hackers could exploit vulnerabilities in these systems for malicious purposes.
To ensure responsible development, we need:
- Diverse Datasets: Training data should be representative of the real world to avoid bias.
- Transparent Algorithms: The working algorithms of these 3d machine vision technologies should be clear and understandable.
- Clear Regulations: Regulations are needed to protect privacy and ensure fair use.
- User Consent and Strong Privacy Protocols: People should have control over their data and robust security measures should be in place.
What’s Next?
Thanks to advancements in deep learning, sensors, and computing power, 3D computer vision is rapidly evolving. This progress could lead to:
- More Accurate Algorithms: Algorithms for 3D reconstruction will become more precise and efficient.
- Real-Time Understanding: 3D systems will be able to understand scenes in real-time.
- Tech Integration: Integration with cutting-edge technology like the Internet of Things (IoT), 5G and edge computing will open new possibilities.
Here are some recommended reads to get a deeper understanding of computer vision technologies:
- What is Computer Vision? The Complete Technology Guide for 2024
- Learn the Use of 3D Computer Vision Technology in AR and VR
- How Computer Vision Technology Makes Advancements in Robotics (2024 Guide)
- A Complete Guide to Image Reconstruction With Computer Vision - 2024 Overview

